Stop running AI pipelines
blind.
LLM observability for AI pipelines — quality, cost and stability control, built for the teams shipping LLMs in production.
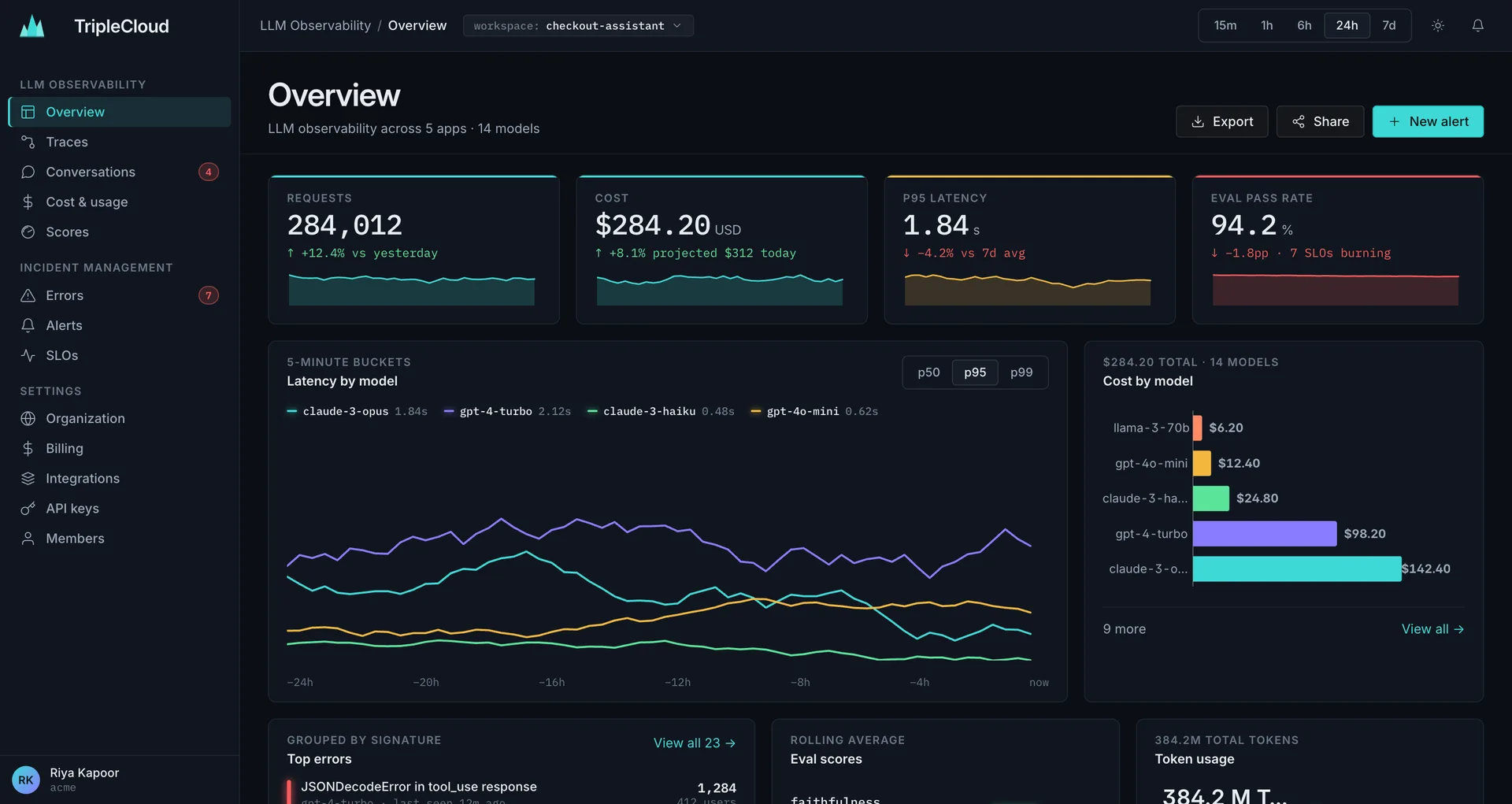
The LLM observability platform
Quality. Cost. Stability.
One platform for AI observability — every signal your AI pipeline emits, from the first token to the last billing line.
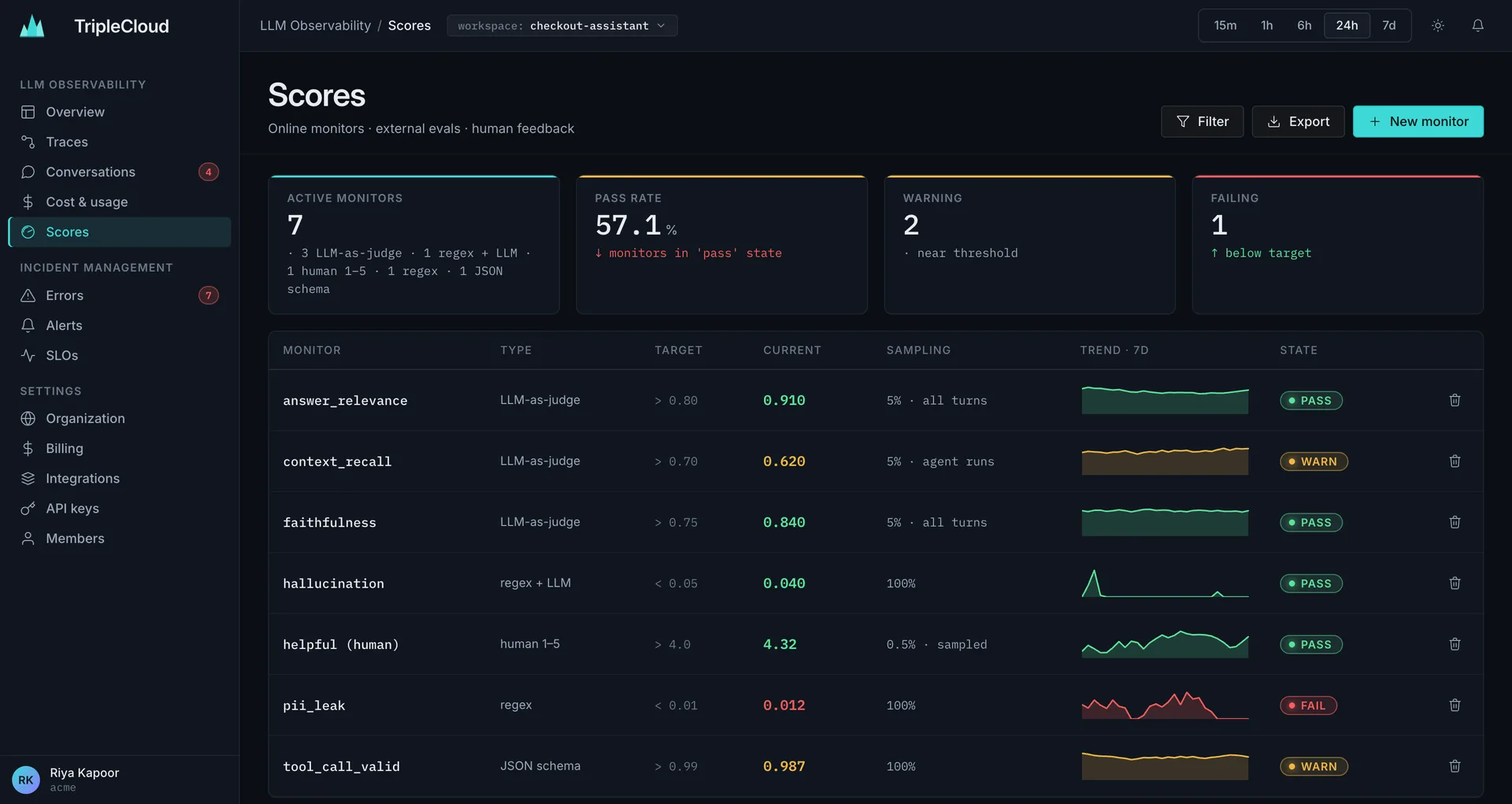
Trust every answer your model ships.
Catch regressions before users do — with online evals and human feedback wired into every turn.
- Scoring: faithfulness, relevance, context recall
- Hallucination & PII leak detection (regex + LLM)
- Human 1–5 feedback loops with sampling controls
- Per-conversation eval pass-rate with drill-down
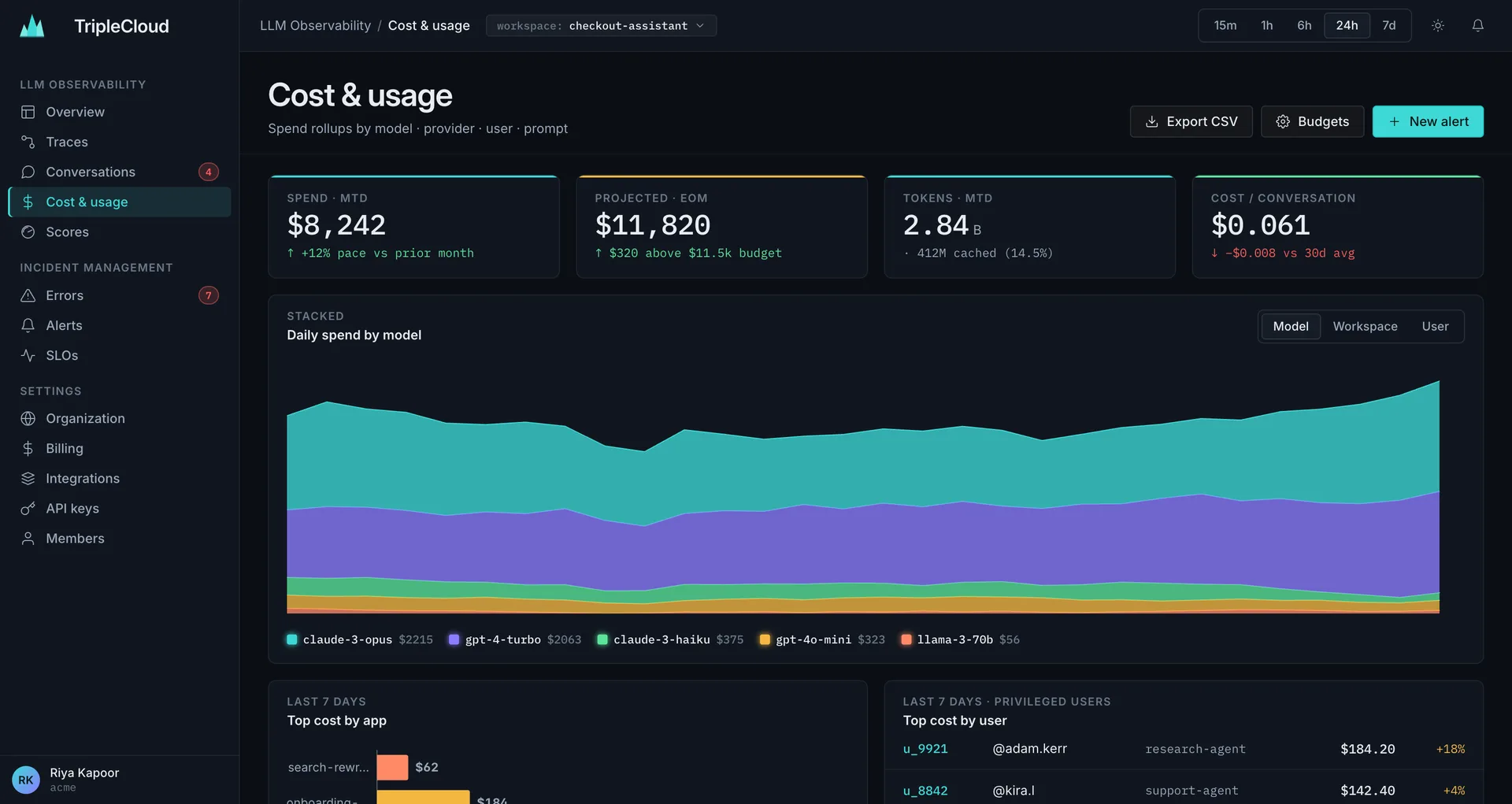
Know what every token costs.
Rollups by model, provider, user and prompt. Projected EOM. Budgets and alerts before you bleed.
- Spend MTD, EOM, cost per conversation
- Daily spend stacked by model / workspace / user
- Token cache hit-rate and savings
- Budgets with multi-channel alerting
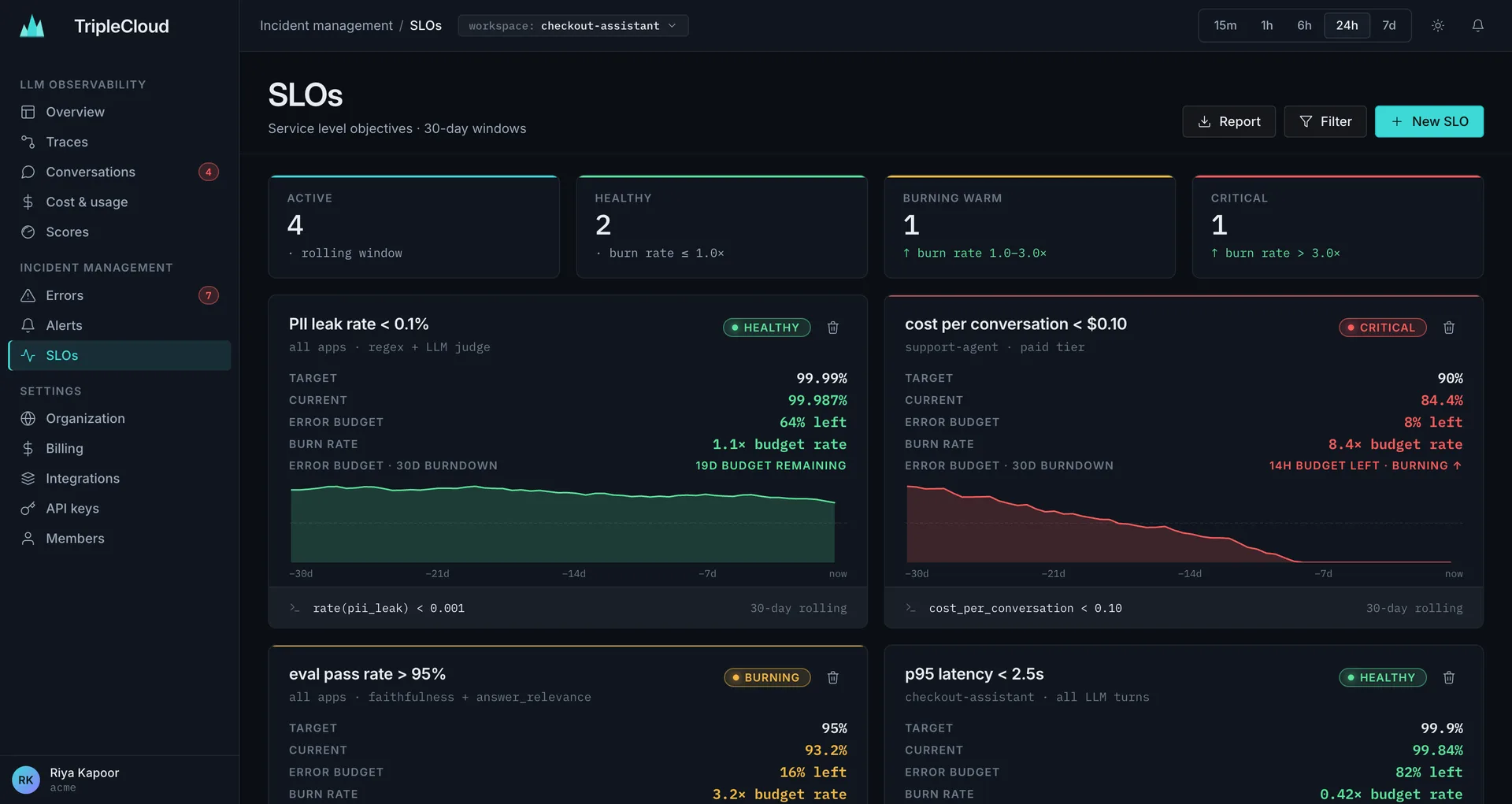
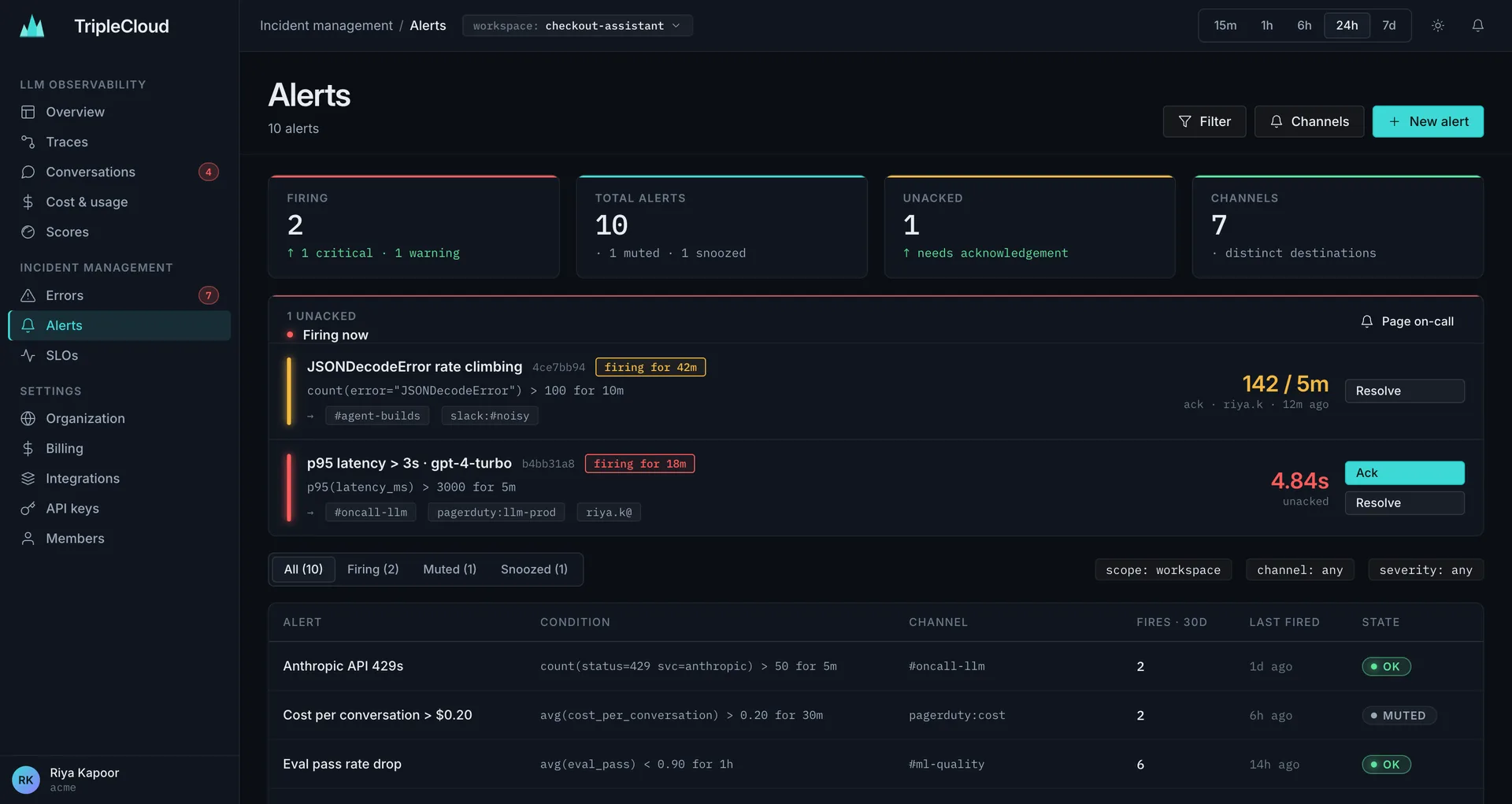
Stay on top of every incident.
Traces, errors, SLOs and on-call paging — the SRE stack your AI agents have been missing.
- Distributed traces across agents and tool calls
- Alerts with PagerDuty / Slack / on-call routing
- SLOs with burn-rate and 30d error budgets
- Provider downtime feeds (OpenAI, Anthropic, etc)
A look inside
LLM observability built for the way AI teams debug.
Pricing
Pay as you go.
Transparent, usage-based. No seats. No platform fee. Bring your storage if you want.
See full pricing details
Open source
The engine is open source.
TripleCloud runs on IceGate — an Apache-2.0 observability data lake engine. Self-host the exact engine we run, or let us operate it. No black box, no lock-in.
OpenTelemetry-native
Point any OTel SDK at IceGate. Exactly-once delivery, straight into open Parquet — no agents to rewrite.
Open formats, no lock-in
Apache Iceberg, Arrow and Parquet under a Rust-native DataFusion query engine. Your data stays portable.
Your storage, your bucket
WAL, catalog and data all live in S3-compatible object storage. Self-host the whole thing under Apache 2.0.